概要描述
本文主要介绍,因为延迟调度策略(Delay Scheduler)的参数配置问题,导致客户的task任务无法触发执行,导致执行时间过长的问题
详细说明
问题现象
客户反馈,多个存储过程,读取text文本表,stage执行时间过长,需要一个小时才能执行完毕
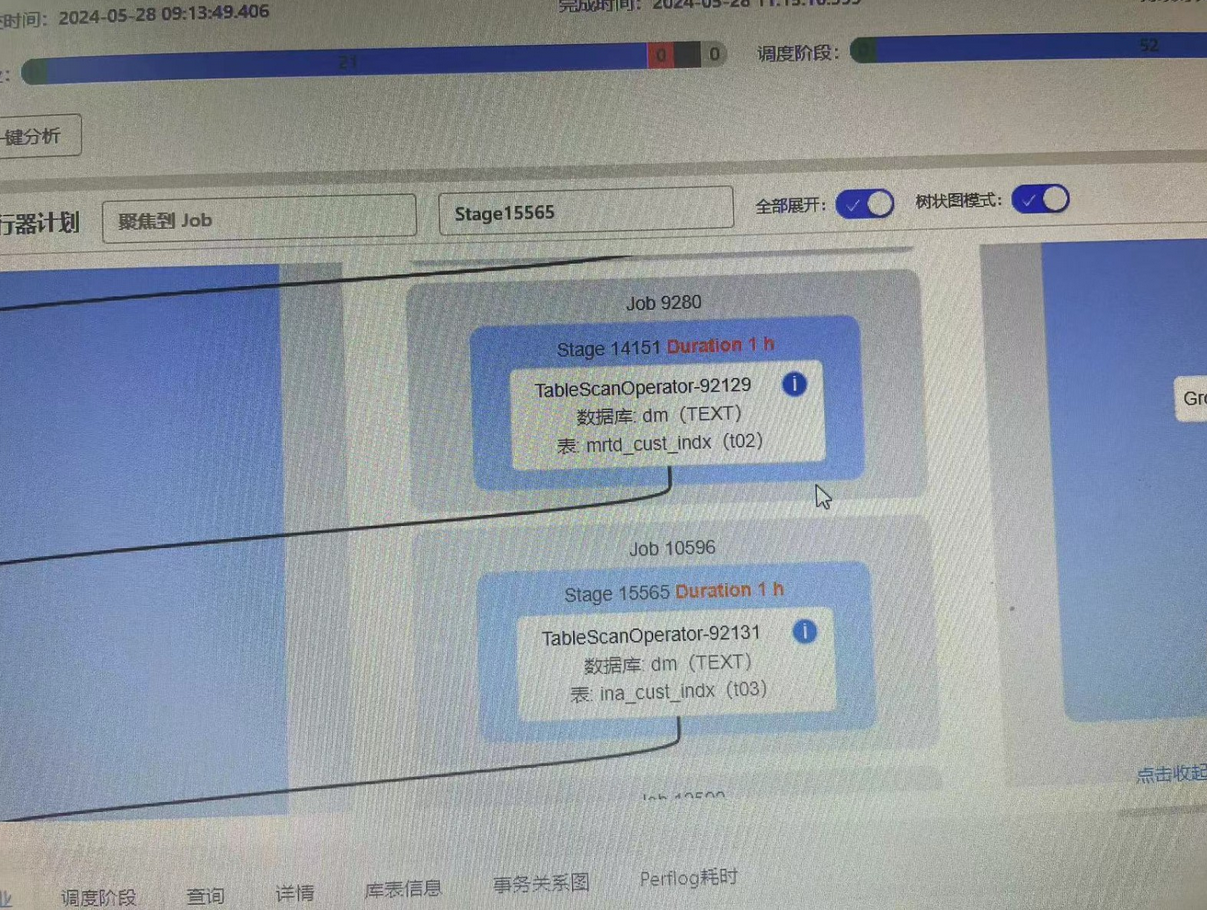
排查思路
a)这些表是普通的text文本表,数据量较少,直接select查询没有任何问题。
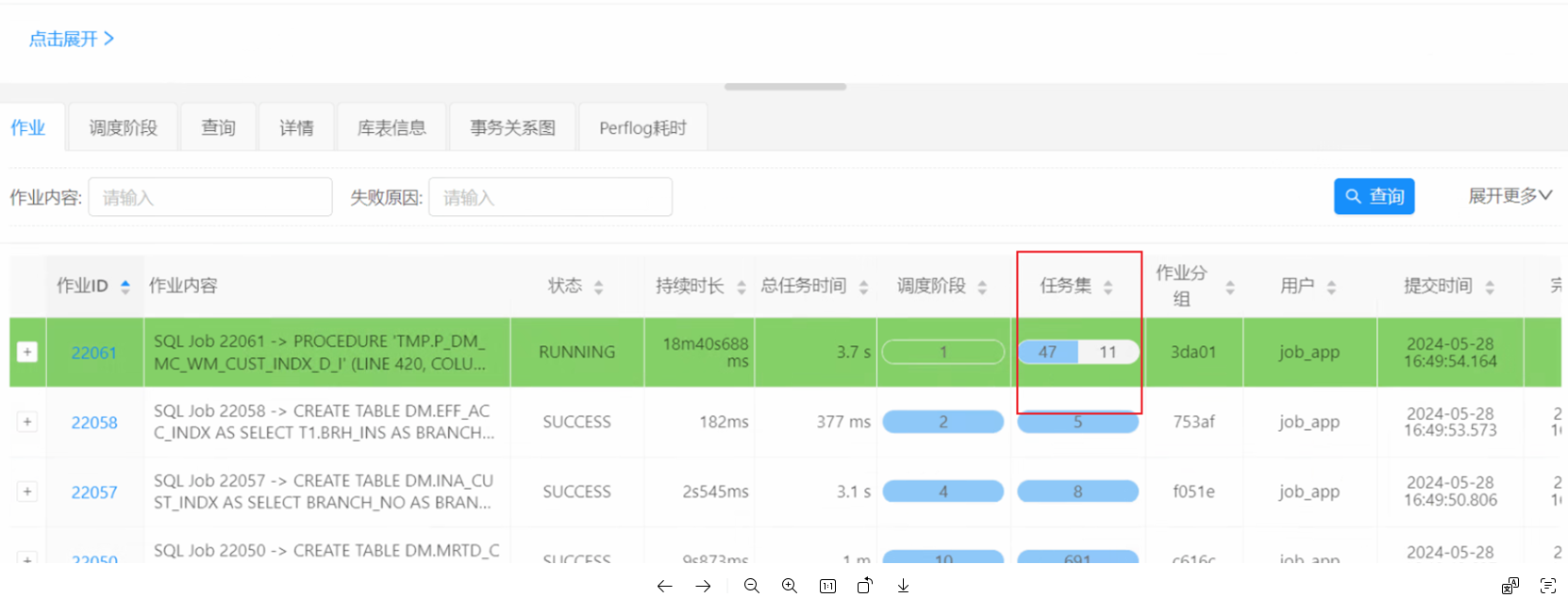
b)DBAService查看stage执行情况,该stage总共59个task,48个很快执行完毕,还有11个一直无法分配到task。对stage中task的duration进行排序,可以看到每个task执行的速度是很快的,只是一直无法分配到task。
d)executor负载很空闲,使用的调度池资源队列也都富余,executor状态也都非常健康。


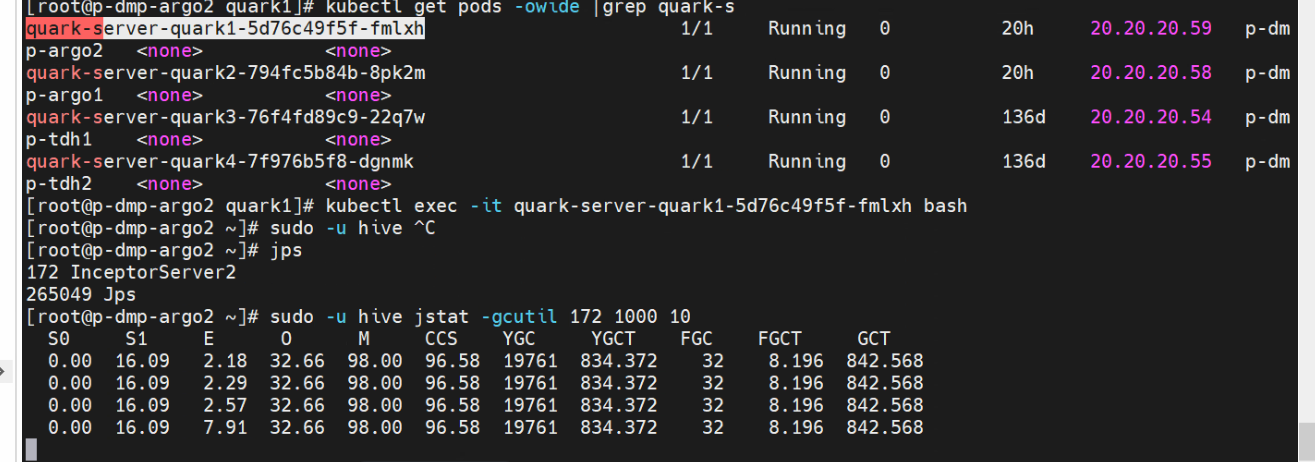
e)检查server 的jstat,也没有GC的情况
f)据客户反馈,之前一直都是正常的,5月22日更新了Argodb Patch,并且对EXTRA_DRIVER_OPTS和EXTRA_EXECUTOR_OPTS进行了调整,其中包含-Dspark.locality.wait.node=3600000的配置,这个参数也就是问题根源所在。
该参数,会导致如果在1个小时等不到 NODE_LOCAL 时的降级延迟时间。
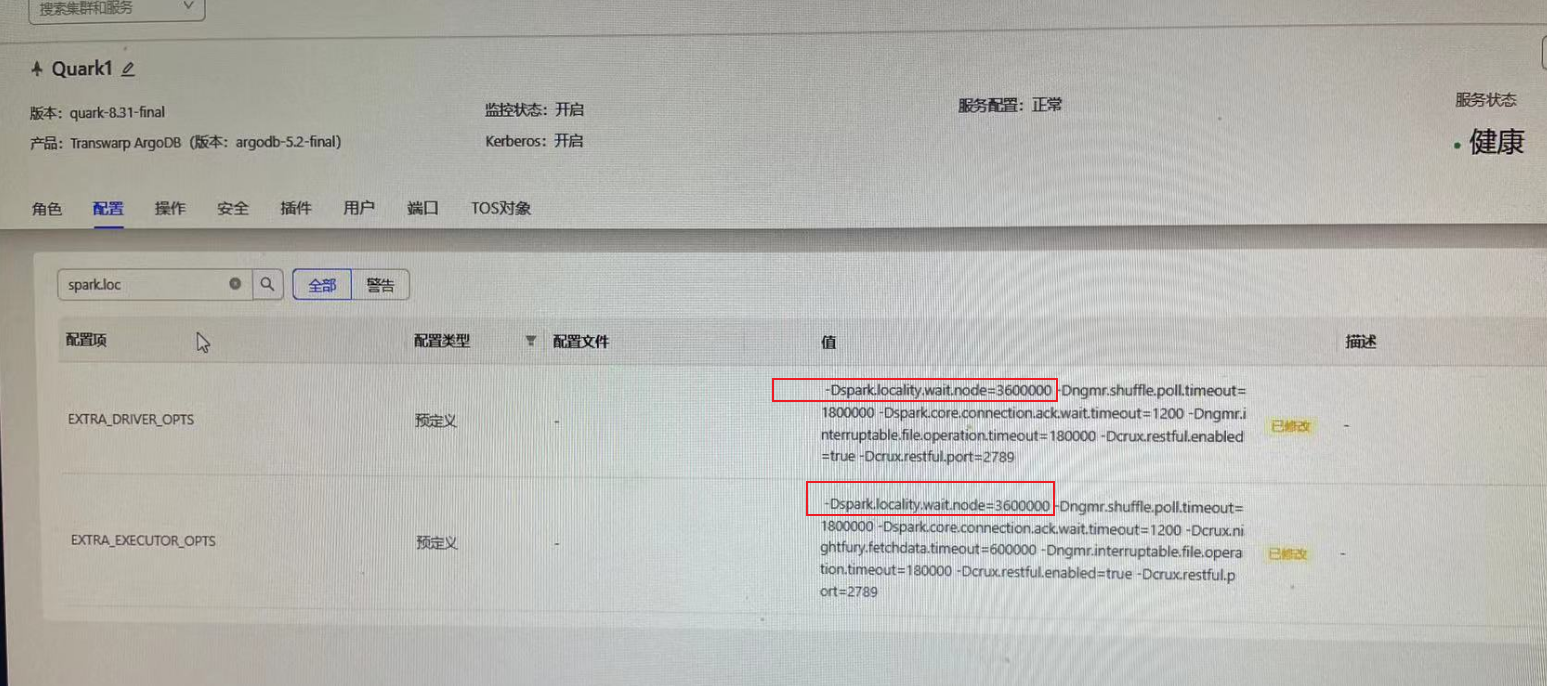
可以通过 任务的 stage 任务集页面查看执行时间比较久的 task 的调度延迟时间。

解决方案:
删除该-Dspark.locality.wait.node=3600000配置,然后quark服务,配置服务,重启。
这里我们介绍一下 延迟调度策略(Delay Scheduler)
Spark在调度程序的时候并不一定总是能按照计算出的数据本地性执行,因为即使计算出在某个Executor上执行时数据本地性最好,但是Executor的core也是有限的,有可能计算出TaskFoo在ExecutorBar上执行数据本地性最好,但是发现ExecutorBar的所有core都一直被用着腾不出资源来执行新来的TaskFoo,所以当TaskFoo等待一段时间之后发现仍然等不到资源的话就尝试降低数据本地性级别让其它的Executor去执行。
举例说明:
比如当前有一个RDD,有四个分区,称为A、B、C、D,当前Stage中这个RDD的每个分区对应的Task分别称为TaskA、TaskB、TaskC、TaskD
在之前的Stage中将这个RDD cache在了一台机器上的两个Executor上,称为ExecutorA、ExecutorB,每个Executor的core是2,ExecutorA上缓存了RDD的A、B、C分区,ExecutorB上缓存了RDD的D分区
然后分配Task的时候会把TaskA、TaskB、TaskC分配给ExecutorA,TaskD分配给ExecutorB,但是因为每个Executor只有两个core,只能同时执行两个Task,所以ExecutorA能够执行TaskA和TaskB,但是TaskC就只能等着,尽管它在ExecutorA上执行的数据本地性是PROCESS_LOCAL,但是因为没有资源,TaskC只能等待,TaskC会设定了一个超时时间,当超过之后还等不到就放弃PROCESS_LOCAL级别,转而尝试NODE_LOCAL级别的Executor,然后它看到了ExecutorB,ExecutorB和ExecutorA在同一台机器上,只是两个不同的jvm,所以在ExecutorB上执行需要从ExecutorA上拉取数据,通过BlockManager的getRemote,底层通过BlockTransferService去把数据拉取过来,因为是在同一台机器上的两个进程之间使用socket数据传输,走的应该是回环地址,速度会非常快,所以对于这种数据存储在同一台机器上的不同Executor上因为降级导致的NODE_LOCAL的情况,理论上并不会比PROCESS_LOCAL慢多少,TaskC在ExecutorB上执行并不会比ExecutorA上执行慢多少。但是对于比如HDFS块存储在此节点所以将Task分配到此节点的情况导致的NODE_LOCAL,因为要跟HDFS交互,还要读取磁盘文件,涉及到了一些I/O操作,这种情况就会耗费较长时间,相比较于PROCESS_LOCAL级别就慢上不少了。
上面举的例子中提到了TaskC会等待一段时间,根据数据本地性不同,等待的时间间隔也不一致,不同数据本地性的等待时间设置参数:
- spark.locality.wait:设置所有级别的数据本地性,默认是3000毫秒
- spark.locality.wait.process:多长时间等不到PROCESS_LOCAL就降级,默认为${spark.locality.wait}
- spark.locality.wait.node:多长时间等不到NODE_LOCAL就降级,默认为${spark.locality.wait}
- spark.locality.wait.rack:多长时间等不到RACK_LOCAL就降级,默认为${spark.locality.wait}
总结数据延迟调度策略:当使用当前的数据本地性级别等待一段时间之后仍然没有资源执行时,尝试降低数据本地性级别使用更低的数据本地性对应的Executor执行,这个就是Task的延迟调度策略。
如果Task的输入数据比较大,那么耗费在数据读取上的时间会比较长,一个好的数据本地性能够节省很长时间,所以这种情况下最好还是将延迟调度的降级等待时间调长一些。而对于输入数据比较小的,即使数据本地性不好也只是多花一点点时间,那么便不必在延迟调度上耗费太长时间。总结一下就是如果数据本地性对任务的执行时间影响较大的话就稍稍调高延迟调度的降级等待时间。