内容纲要
概要描述
本文描述TDC修改时间(过去时间 和 未来时间)对集群的影响
PS:不讨论超过证书范围内的过去时间和未来时间
详细描述
1 修改成未来时间
将时间往几天后调整对集群没有特殊影响,并且重启pod后可以正常running并提供服务。
2 修改成过去时间
对集群的影响会比较大
- 当调整时间超过集群的创建时间,那么就需要重新生成所有的k8s相关证书以及秘钥后重启kubelet,k8s-proxy,apiservice等服务恢复正常。(不讨论极端场景)
- 当调整时间没有超过集群的创建时间,会有部分pod处于异常状态,可以通过查看pod日志以及容器日志来排查问题,测试中发现大多数问题都与集群的网络验证超时,导致warpdrive服务无法正常与网络通讯,最终会导致pvc无法正常创建而使得pod启动失败。同时重启pod时因为将时间往前调整也可能会出现conflict container name be used 的问题。
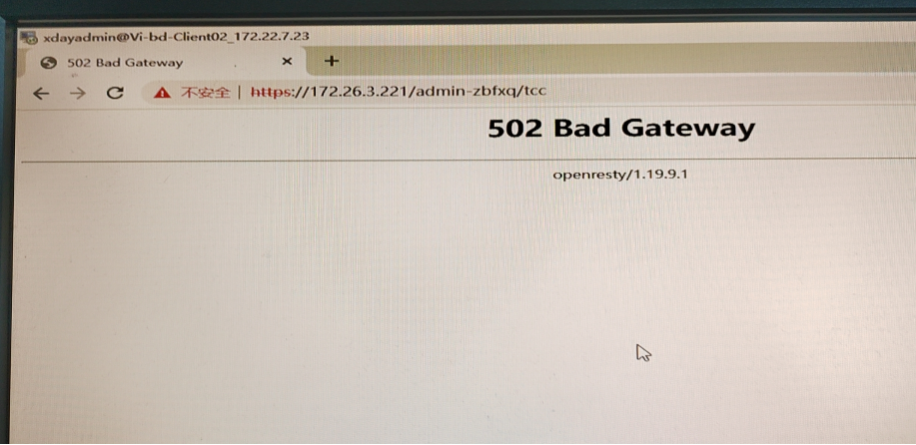
此时打开tcc页面,会出现502 Bad Gateway的报错
解决方案
重启相关的网络服务:coredns、ingress-nginx-ingress-controller、ingress-nginx-ingress-default-backend、k8s-apiserver、kubelet、warpdrive
kubectl delete pod coredns-coredns-xxxxx -n kube-system
kubectl delete pod ingress-nginx-ingress-controller-xxxxxx -n kube-system
kubectl delete pod ingress-nginx-ingress-default-backend-xxxxxx -n kube-system
//etcd节点
mv /opt/kubernetes/manifests-multi/kube-apiserver.manifest /tmp
mv /tmp/kube-apiserver.manifest /opt/kubernetes/manifests-multi/
systemctl restart kubelet
systemctl restart warpdrive然后重启异常的组件pod
如果pod报错conflict container name be used,到pod所调度的节点
docker rm 掉对应的已经Exited的容器,即可等待pod正常运行。
当服务出现异常时如tdc-eco,租户相关,大数据组件等,重启服务即可