概要描述
旧版本 CA 证书于 2025/12/7 日过期,需要及时进行证书的更新防止 TOS 集群不可用
对于 TDC 5.X 来说,只要环境内部有 manager 集群(或者说 TOS 2.x),不管是on manager架构,还是纳管的 manager 集群,都需要进行续签。
需要注意的是,续签动作是针对 TOS 集群,所以可以去具体的 TOS 集群中确认 ca 证书的时间。
详细说明
- 续签注意事项
- 获取更新脚本
- 续签集群(先主集群,后子集群)
4. (可选)续签集群 guardian 证书 - 执行 TDC FED rejoin
1. 续签注意事项
-
准备工作,明确TDC架构,按集群维度进行 CA 证书续签。
TDC5 属于多集群架构,在续签前,需要明确续签的 TOS 集群属于 TDC 的主集群,还是子集群。 -
如果涉及到主集群续签,操作过程中会重启 TDC 的 pod,会影响 TDC 的登录功能。请合理安排停机时间。
-
如果是子集群续签,不影响集群运维和使用。
-
如果续签内容中包含主集群续签,请先续签主集群;
-
如果有多个子集群需要续签,可以先续签子集群(子集群之间互不影响,可以同时续签多个子集群)。
-
最后再进行 TDC FED rejoin 操作(每次只能操作一个子集群,不能并行操作)。
无论是主集群还是子集群续签,本质都是集群证书续签(主集群、子集群都需要操作) + TDC FED rejoin(只在主集群操作) 。
2 获取更新脚本
点击链接,根据 TOS Master 服务器架构,下载对应的CA证书更新工具 ca-renewal-v13.tar.gz
根据即将执行脚本的 TOS Master 节点的架构,选择对应的脚本工具。
tos maste 节点是 X86 架构,就上传 ca-renewal-v13.tar.gz
tos maste 节点是 ARM 架构,就上传 ca-renewal-v13-arm64.tar.gz
在 ca-renewal 目录下,执行以下命令分别安装 sshpass / cfssl / cfssljson 这三个命令
# 解压更新包 进入目录
$ tar -zxvf ca-renewal-v13.tar.gz
$ cd ca-renewal
# 安装 sshpass
$ rpm -ivh sshpass-1.06-2.el7.$(uname -p).rpm
# 安装 cfssl 相关命令
$ cp -pr cfssl* /usr/local/bin/.3 续签集群ca证书
3.1 填写集群节点信息
3.1.1、生成集群节点信息
$ bash gen-hosts.sh
# 执行此脚本会在 ca-renewal 目录下生成 hosts.txt,里面仅包含集群节点的 hostname、ip 及 tos角色执行上述脚本后,需要手动检查 hosts.txt
- 第 4 列补充节点的 ssh 端口,
- 第 5 列对应 ssh 的用户名,
- 第 6 列对应 ssh 密码
如果节点间使用 root 免密的话 ,hosts.txt 中的 用户名、密码 无需填写。
标准的hosts文件参考
$ cat ca-renewal/hosts.txt
node01 172.18.120.115 master 22 test Warp@1234
node02 172.18.120.113 master 22 test Warp@1234
node03 172.18.120.114 master 22 test Warp@1234
node04 172.18.120.112 worker 22 test Warp@1234注意:
如果使用非 root 用户执行脚本,在执行 tos 续签脚本前,需要给该用户在对应节点上添加 sudo 权限,比如用 visudo 命令编辑 sudo 文件
$ visudo
# 在文件最后一行添加对应用户的sudo权限并保存修改
_test-name245 ALL=(ALL) NOPASSWD: ALL3.1.2 续签集群CA证书
修改 ca-renewal-manager.sh 脚本,注释如下2行
$ vi ca-renewal-manager.sh
echo "INFO: Start Update Manager db with new ca"
#bash $basedir/09-update-manager-db.sh || exit 1 #注释掉
echo "INFO: Update Manager db with new ca Succeeded"
echo "INFO: Start Update Manager metainfo with new ca"
#bash $basedir/09-update-manager-metainfo.sh || exit 1 #注释掉
echo "INFO: Update Manager metainfo with new ca Succeeded"执行 ca-renewal-manager.sh 脚本进行证书续签。
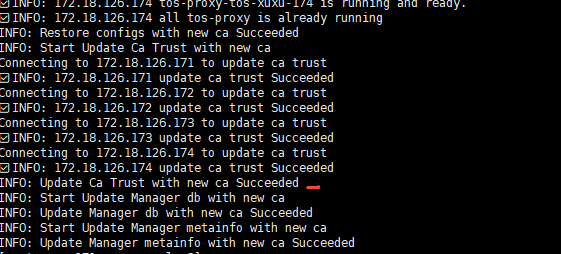
$ bash ca-renewal-manager.sh以下两种结果输出都属于正常输出。
正常执行结果1:

正常执行结果2:
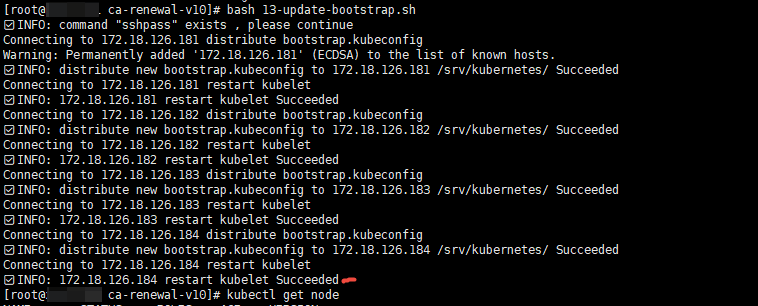
3.1.3、更新集群 bootstrap.kubeconfig
$ bash 13-update-bootstrap.sh正常执行结果:
4. (可选)续签集群 guardian 证书
跳过,无需执行!
5、TDC FED rejoin
5.0 rejoin 说明
-
如果集群是manager 6系列,以下方案可能不能覆盖,rejoin的具体操作内容请咨询tdc团队进行处理。
-
在 集群完成 续签后,还需要在 TDC FED 上进行rejoin 操作,用来激活和更新 FED 和 续签集群 之前的控制关系。
-
执行节点为 TDC 主集群(即 fed 集群)的任一 master 节点。
注意:执行 rejoin 操作,必须在 集群CA证书更新完毕 之后执行。
5.1 执行 rejoin 操作
1、将 完成 CA 证书续签的集群 的 kubeconfig 配置文件 copy 至 TDC master 节点上
2、修改 续签集群 kubeconfig的 api IP 为 续签集群 TOS master IP
- 修改续签集群 kubeconfig 的 api IP 为 续签集群 TOS master IP,不能是 127.0.0.1
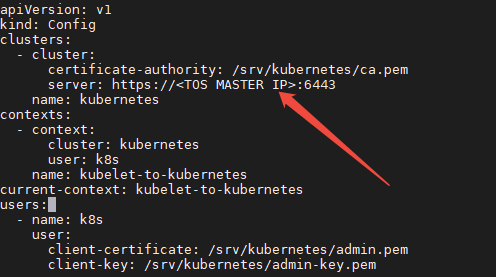
3、使用 tosfedctl 工具,执行以下命令
$ tosfedctl rejoin CLUSTER_NAME --cluster-kubeconfig= --enable-network=true
# CLUSTER_NAME 是需要已经续签完成的集群。
# KUBECONFIG 是已经续签完成的集群的 kubeconfig,(是从已经续签完成的集群的 kubeconfig 文件 copy 至主集群工具所在目录)

操作示例:
TDC master (FED 集群)任意节点之一 作为 TDC IP
续签集群的 TOS master 任意节点之一作为 TOS MASTER IP ,续签集群名称为 TOS CLUSTERNAME
# 获取 cluster name 用于 rejoin 命令
$ tosfedctl get cluster
# 在 TDC master 节点上准备好rejoin 目录,这里使用 /opt/transwarp
$ cd /opt/transwarp
# 创建以续签集群为名的目录
$ mkdir -p /opt/transwarp/rejoin-cluster/
# 将续签集群的配置文件copy至该目录,如果是本集群copy 请使用 cp -pr 命令(TDC on manager续签主集群场景)
$ scp -r :/srv/kubernetes/ /opt/transwarp/rejoin-cluster//.
检查续签集群的kubeconfig文件,确保cluster server 的 IP 不为127.0.0.1 ,应该为 续签集群的 TOS master IP
# 实际操作中请替换为 TOS MASTER的实际名称和IP
$ cat /opt/transwarp/rejoin-cluster//kubernetes/kubeconfig
# 执行rejoin 并等待命令返回 successful
$ tosfedctl rejoin --cluster-kubeconfig=/opt/transwarp/rejoin-cluster//kubernetes/kubeconfig --enable-network=true
5.2 更新数据库
请先上传 TOS BASE 的最新包不区分服务器架构 TOS-Base-2.1.x.tar.gz,确保 TDC 环境内部的TOS metainfo 已经更新。
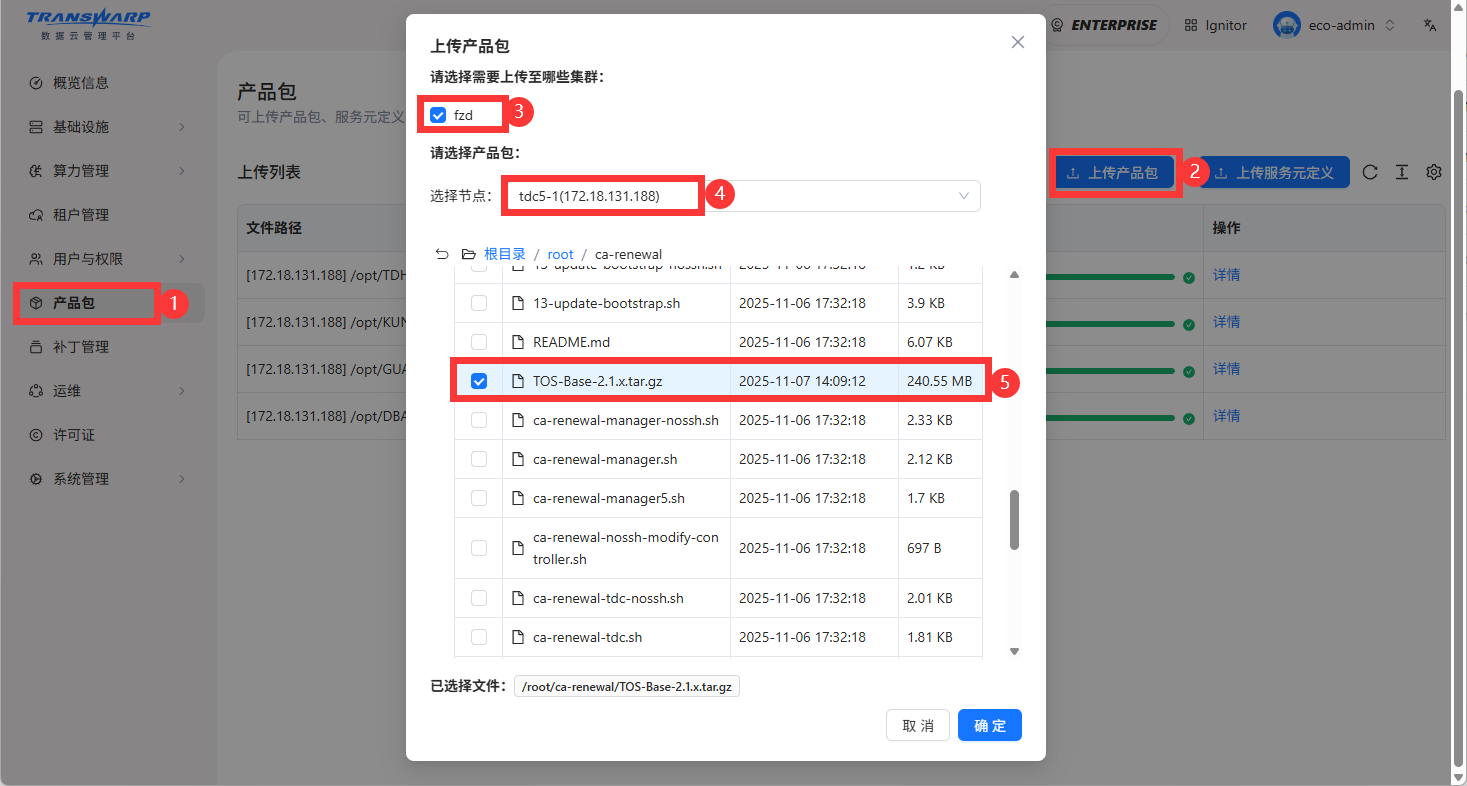
这一步非常重要,否则可能会导致后续在TOS 配置服务场景中 CA证书刷回旧版本。请务必上传最新 TOS BASE 产品包。
更新TDC数据库,步骤如下:
- 执行备份脚本,备份 cluster_config 表内容
- 使用脚本更新 TDC 数据库中 cluster_config 表中的相关证书记录
1、执行备份脚本,备份 cluster_config 表内容
#!/bin/bash
# 获取当前时间戳
TIMESTAMP=$(date +%Y%m%d%H%M%S)
BACKUP_TABLE="cluster_config_$TIMESTAMP"
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1"
}
# 数据库查询函数
db_query() {
local query="$1"
kubectl --kubeconfig=/srv/kubernetes/kubeconfig -ntdcsys exec kundb-kundb-0 -- mysql -hkundb-kundb.tdcsys.svc -ptranswarp -uvt_app -P3306 -D tdc_fed -NB -e "$query" 2>/dev/null
}
check_success() {
if [ $? -eq 0 ]; then
log "执行命令成功"
else
echo "执行命令失败"
exit 1
fi
}
# 主函数
main() {
# 备份整个 cluster_config 表
log "备份 cluster_config 表到 $BACKUP_TABLE..."
db_query "CREATE TABLE $BACKUP_TABLE AS SELECT * FROM cluster_config;"
check_success
backup_count=$(db_query "SELECT COUNT(*) FROM $BACKUP_TABLE;")
log "备份完成,共备份 $backup_count 条记录"
}
# 执行主函数
log "开始备份数据库表 cluster_config ..."
main
log "$BACKUP_TABLE备份完成,请进行表更新操作"2、执行更新脚本,更新 TDC 数据库中 cluster_config 表中的相关证书记录
#!/bin/bash
if [ $# -ne 1 ];then
echo "usage: please enter cluster name"
exit 1
else
clustername=$1
echo "cluster name is $clustername"
fi
# 获取当前时间戳
TIMESTAMP=$(date +%Y%m%d%H%M%S)
BACKUP_TABLE="cluster_config_$TIMESTAMP"
CURRENT_PATH=/opt/transwarp/rejoin-cluster
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1"
}
# 数据库查询函数
db_query() {
local query="$1"
kubectl --kubeconfig=/srv/kubernetes/kubeconfig -ntdcsys exec kundb-kundb-0 -- mysql -hkundb-kundb.tdcsys.svc -ptranswarp -uvt_app -P3306 -D tdc_fed -NB -e "$query" 2>/dev/null
}
check_success() {
if [ $? -eq 0 ]; then
log "执行命令成功"
else
echo "执行命令失败"
exit 1
fi
}
# 主函数
main() {
# 查询cluster_id
cluster_id=$(db_query "SELECT id FROM cluster WHERE name = '$clustername';")
check_success
if [[ -z "$cluster_id" ]]; then
log "警告: 没有找到IP $ip 对应的clusterId"
exit 1
fi
local conf_dir="$CURRENT_PATH/$clustername/kubernetes"
if [[ ! -d "$conf_dir" ]]; then
log "错误: 配置目录 $conf_dir 不存在"
exit 1
fi
# 更新 cluster_config 表:将 .pem 类型配置的 value 替换为 $conf_dir 下同名文件的内容
local pem_keys_and_ids
# 查询 key 和 config id,确保能精准更新
pem_keys_and_ids=$(db_query "
SELECT \key\, id
FROM cluster_config
WHERE clusterId = '$cluster_id'
AND \key\ LIKE '%.pem';
")
check_success
# 如果没有匹配的记录,跳过
if [[ -z "$pem_keys_and_ids" ]]; then
log "错误: 没有找到需要更新的 .pem 配置项"
exit 1
fi
# 逐行处理查询结果
while IFS=$'\t' read -r key config_id; do
local file_path="$conf_dir/$key"
if [[ ! -f "$file_path" ]]; then
log "错误: 配置文件不存在,失败文件: $file_path"
exit 1
fi
# 读取文件内容(保留换行符等)
local file_content
file_content=$(cat "$file_path")
if [[ $? -ne 0 ]]; then
log "错误: 无法读取文件 $file_path"
exit 1
fi
# 执行更新(使用 config.id 定位)
db_query "
UPDATE cluster_config
SET value = '$file_content'
WHERE id = '$config_id';
"
check_success
log "已更新配置项: $key"
done <<< "$(echo -e "$pem_keys_and_ids")"
}
# 执行主函数
log "开始更新集群 $clustername的 cluster_config 表的证书记录..."
main
log "集群 $clustername的表证书记录处理完成"