概要描述
本文主要介绍,holodesk表在做了 DROP 误删操作之后,如何恢复,仅供参考。
一般来说,holodesk表的自动清理策略,每1小时清理7天之前的回收站文件:
CLEAN_TRASH_TIME_PERIOD_S:数值类型,表示清理回收站定时任务触发周期,单位为秒,最小配置600,默认值3600s,也就是1小时;
TABLE_KEEP_IN_TRASH_TIME_S:数值类型,表示处于回收站中表的最小保留时间,单位为秒,最小配置600,默认值604800s,也就是7天;
5.x arogdb参数为TDDMS的:
shiva.master.scheduler.clean_trash_period_s 是每隔多久检测一次
shiva.master.scheduler.keep_trash_time_s 是回收站文件保留期限
注意:
truncate / drop table … purge 操作不会进入回收站,无法找回
解决方案
测试环境:Argodb5.2.3 (quark 8.31.2 + tddms 2.3.4)
1.创建样例表,并插入一条数据
CREATE TABLE EMP_HOLO(
EMPNO int,
ENAME string,
JOB string,
MGR INT,
HIREDATE DATE,
SAL INT,
COMM INT,
DEPTNO INT
)CLUSTERED BY (empno) INTO 3 BUCKETS
STORED AS HOLODESK;
INSERT INTO EMP_HOLO VALUES (7369,'SMITH','CLERK',7902,tdh_todate('17-12-1980','dd-mm-yyyy'),800,NULL,20);2. 将表DROP掉
DROP TABLE IF EXISTS EMP_HOLO;3. 记录表的table id和table name
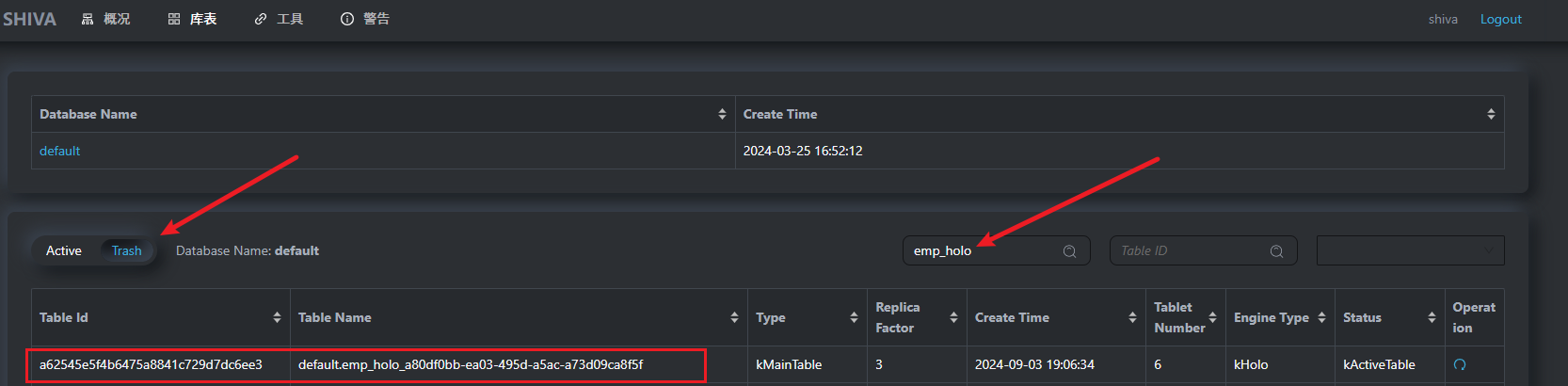
可以到 TDDMS Webserver – 库表 – Trash 页面,根据 Table Name搜到对应的表。
也可以通过curl命令获取
TABLE id : a62545e5f4b6475a8841c729d7dc6ee3
TABLE name : default.emp_holo_a80df0bb-ea03-495d-a5ac-a73d09ca8f5f
记下来,step4 会用到。
4. 挪出回收站 restore trash
有两种姿势可以将shiva表从trash中挪出:
shiva web 的recover table 按钮
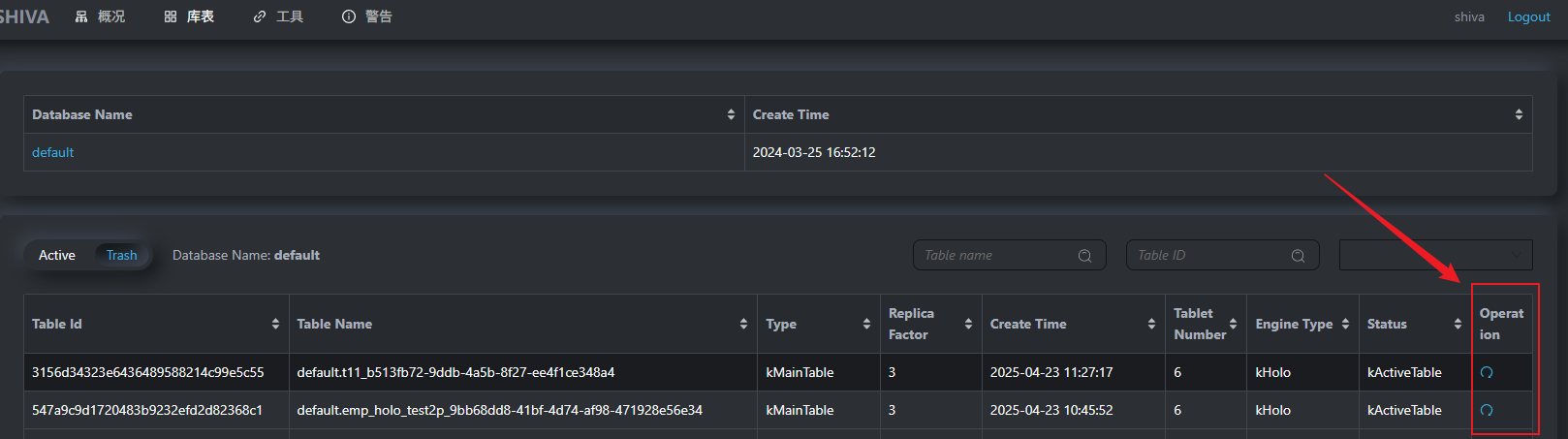
curl命令
curl -u shiva:shiva -X PUT "172.22.23.2:4567/trash?table_id=a62545e5f4b6475a8841c729d7dc6ee3&new_table_name=default.emp_holo_a80df0bb-ea03-495d-a5ac-a73d09ca8f5f"
执行上述任意一种操作后,仅在shiva中恢复了表,但是metastore中并不感知表已经恢复了,需要执行下面的sql语句来映射好meta信息。
5. 创建待恢复的表
--重建该表
CREATE TABLE EMP_HOLO(
EMPNO int,
ENAME string,
JOB string,
MGR INT,
HIREDATE DATE,
SAL INT,
COMM INT,
DEPTNO INT
)CLUSTERED BY (empno) INTO 3 BUCKETS
STORED AS HOLODESK;为什么不直接指定原来的holodesk.tablename?
holodesk内表创建的时候如果指定已存在的holodesk.tablename,会报shiva表已存在:
Can not create table: Table default.emp_holo_a80df0bb-ea03-495d-a5ac-a73d09ca8f5f already exists ; use CREATE EXTERNAL TABLE instead to
如果表是分区表,需要在这一步手动逐个添加分区,ALTER TABLE t22 ADD PARTITION (p='p1');,数据分区详情可以在shiva界面上查看。
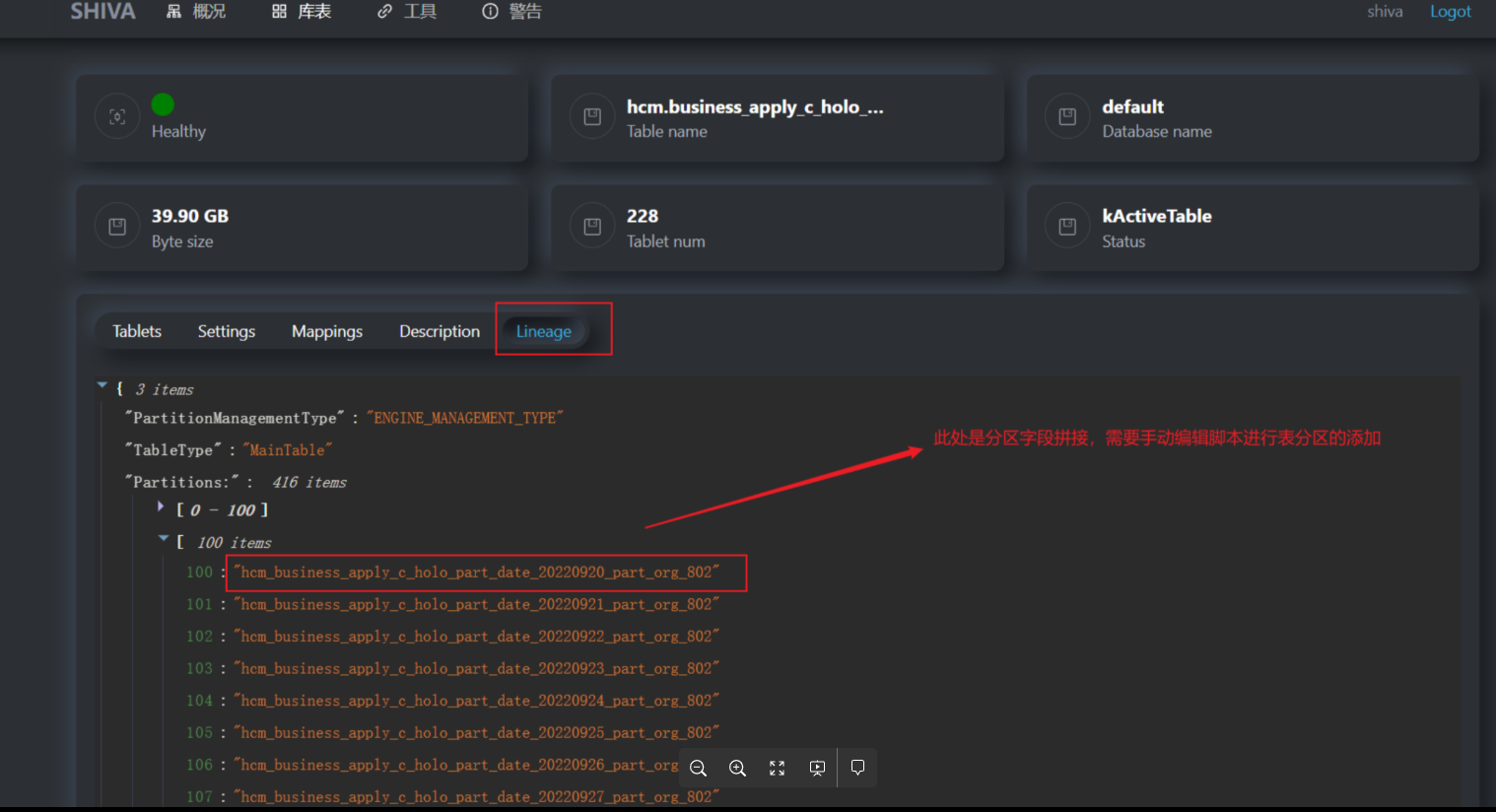
这一步是为了保证,在元数据中,创建出对应的分区。因为 add pattition 的过程分两步
- 在 Metastore 中创建分区 Schema

- 在 TDDMS 中的表创建 Section(分区)
而执行第6步后,因为 Section 已存在,则无法再添加。
6. 通过tblproperties关联shiva表
将前面的Table name放置到下面的holodesk.tablename属性里面去
ALTER TABLE EMP_HOLO SET TBLPROPERTIES ('holodesk.tablename'='emp_holo_a80df0bb-ea03-495d-a5ac-a73d09ca8f5f' );验证数据正常可查。
FAQ
1. 分区表,重建后,查询失败
问题原因:新建的空表,表名与原表不同,导致添加分区时,在元数据里拼接的 partition_name 与 原表的 partition_name 不同。
分区表恢复时,创建的空表,务必与原表名一致,以保证 pattitions_v 中显示的 location 里的 pattition_name 与原表一致
--简化复现sql:
DROP TABLE IF EXISTS t11;
CREATE TABLE t11(id INT ,name STRING )PARTITIONED BY (p STRING ) STORED AS HOLODESK;
INSERT INTO t11 VALUES (1,'a','p1');
DROP TABLE t11;
curl -u shiva:shiva -X PUT "172.22.23.2:4567/trash?table_id=39b3ded5b530463f8858b2bfa96173d3&new_table_name=default.t11_b7a65124-71b9-4935-baf4-81abe7158c5e"
--这里想通过不一致的表名来恢复
DROP TABLE IF EXISTS t22;
CREATE TABLE t22(id INT ,name STRING )PARTITIONED BY (p STRING ) STORED AS HOLODESK;
ALTER TABLE t22 ADD PARTITION (p='p1');
ALTER TABLE t22 SET TBLPROPERTIES ('holodesk.tablename'='default.t11_b7a65124-71b9-4935-baf4-81abe7158c5e');
--查询报错
SELECT * FROM t22;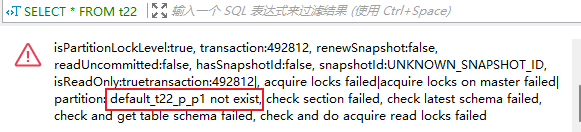
3. 增大shiva回收站保存周期为70天
TABLE_KEEP_IN_TRASH_TIME_S:数值类型,表示处于回收站中表的最小保留时间,单位为秒,最小配置600,默认值604800s,也就是7天。
如需保留更长时间,可通过如下接口配置:
[root@kv1~]# curl -u shiva:shiva -XPUT "172.22.23.2:4567/config?config=TABLE_KEEP_IN_TRASH_TIME_S,6048000"
{"log_id": 1745344848645,"code": 0,"msg": "ok"}
[root@kv1~]#
[root@kv1~]# curl -u shiva:shiva -X GET "172.22.23.2:4567/config"
{"log_id": 1745344848650,"code": 0,"msg": "ok","config": {"configs": [{"value": "true"},{"key": "STORE_BALANCE_ENABLED","value": "true"},{"key": "STORE_MIGRATE_OUT_PERCENTAGE","value": "10"},{"key": "STORE_MIGRATE_IN_PERCENTAGE","value": "70"},{"key": "TABLE_KEEP_IN_TRASH_TIME_S","value": "6048000"},{"key": "STORE_DO_BALANCE_THRESHOLD","value": "20"}]}}