概要描述
ArgoDB海量实时数据写入场景中,为同时满足实时数据写入大量吞吐以及查询性能,ArgoDB引入了分层的概念,设计了 Level Write 模式。
在这里我们将新鲜写入的实时数据称为 Level0 层,这一层的特点是可能存在主键重复,数据读取时采用 MOR(merge on read)模式,保证读取时的主键唯一性。
而实时写入之后经过数据规整加速查询的数据称为 Level1 层,该层的特点是COW(copy on write)主键经过合并,互相间不存在主键重复情况,可通过Native向量计算引擎加速数据查询。
该模式虽然增加了数据延迟,但保持了MOR模式的快速写入特性,以及COW的快速查询特性。可以满足ArgoDB一些客户的实际需求。这里功能点提到的Level0Compact就是将新写入的实施数据进行逐渐去重以及转换成规整的有利于查询性能格式的过程。
原理介绍
Performance表 rowkey分两层:Level0 与 level1 。
level0 只有base文件,可能有重复rowkey,通过Compact之后合到Level1,保证Level1 Rowkey唯一。
-
实时数据写入:Slipstream 或 Sink API 等方式将实时流数据写入至 Rowkey 表,默认进入到 level0,通过CompactService自动合并到 level1 。
-
批量数据写入:支持使用 BATCHINSERT 或 INSERT INTO SELECT 批量插入数据至 Rowkey 表中,会先写入到 level0,写入的同时立刻触发去重合并(level0 compact)至快读层(level1),实现批量数据的实时读取。参考截图:
详细说明
测试环境:Argodb6.0.4
1. 创建rk表
DROP TABLE IF EXISTS smallholo;
CREATE TABLE smallholo
(id INT ,
name STRING
)STORED AS HOLODESK
tblproperties("holodesk.rowkey"="id");2. 插入一条数据
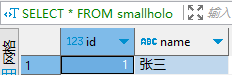
INSERT INTO smallholo3 SELECT 1,'张三' FROM system.dual;DBAService页面查看,Query会多起一个job,做 RowKey level0 compact

SELECT * FROM smallholo; 正常查询出数据。
3. 设置如下参数,禁止自动合并
--默认true,控制quark是否向compactservice提交任务
SET holodesk.compaction.trigger.enabled=FALSE;
--默认true,控制performance rowkey表 insert/update/delete 操作是否自动触发compaction,为true表示数据变更会即时可见。
SET holodesk.rowkey.sql.trigger.compact=FALSE;4. 再次插入一条数据
INSERT INTO smallholo SELECT 2,'李四' FROM system.dual;DBAService页面查看,不再做 level0 compact 的 job :

SELECT * FROM smallholo; 无法查询到新增的那条记录
5. 执行compact level0
quark触发的compaction使用quark的资源队列,level0 仅触发level0 compaction,full 触发 level0 + level1
ALTER TABLE smallholo COMPACT 'level0';两条数据可正常查询:
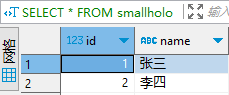
或者可以通过 no_delay 这个 hint 强制查询前必须触发一次 level0 compaction,也是一样的效果
SELECT /* +no_delay */ * FROM smallholo;