概要描述
过期后,tos 服务不可用,本文介绍一种 CA 证书过期后的续签步骤。

需要注意的是,本手册仅建立在CA证书过期,但docker服务和ETCD服务还可以正常运行的环境中。
如果当前环境内部docker服务和ETCD服务不正常,请先恢复docker和ETCD服务,再进行CA证书的续签操作。
详细说明
- 准备工具
- 获取信息
- 唤醒tos,并执行续签
1 准备工作
1.1 获取更新脚本
根据 TOS MASTER 节点的 cpu 架构 获取对应的更新包,并将安装包放置于 环境的 TOS MASTER节点。
点击链接,根据 TOS Master 服务器架构,下载对应的CA证书更新工具 ca-renewal-v13.tar.gz
1.2 安装所需命令
解压更新包,获得 ca-renewal 目录。
在 ca-renewal 目录下,执行以下命令分别安装 sshpass / cfssl / cfssljson 这三个命令
# 解压更新包 进入目录
cd ca-renewal
# 安装 sshpass
rpm -ivh sshpass-1.06-2.el7.$(uname -p).rpm
# 安装 cfssl 相关命令
cp -pr cfssl* /usr/local/bin/.1.3 确认前置服务可用
如果环境节点较多,以下服务确认 TOS master 的情况即可:
docker : systemctl status docker 确认 是否为 active (running)

kubelet :systemctl status kubelet 确认 是否为 active (running)

haproxy :systemctl status haproxy 确认 是否为 active (running)

etcd :TOS master 节点的 docker ps -a | grep etcd CREATED 时间相同的容器的 STATUS 为 Up 没有 Exited

如果 docker 和 etcd 不正常,需要修复 docker 和 etcd 后再执行后续续签操作。
如果 docker 服务不正常,无法进行CA证书的更新。
如果 etcd 服务不正常,会有数据丢失的情况出现。
2、获取相关信息
2.1 获取 相关信息
需要获取以下两个信息,kubernete IP 和 Master、worker 节点
-
kubernete IP:集群节点的主机名和IP
# 在 TOS master 节点 $ grep -r service-cluster-ip-range /opt/kubernetes/manifests-multi tos-apiserver.manifest: --service-cluster-ip-range=10.10.10.0/24 # 可以看到 10.10.10.0 那么 kubernete IP 对应就是 10.10.10.1
-
TOS Master 主机名和 IP
如果 manager 页面仍可登录,也可以去manager页面获取信息。
全局服务 — TOS — 角色
TOS master 为 master 节点
TOS slave 为 worker 节点
PS:如果 manager页面也不可用,但 manager 数据库仍可连接,请从数据库获取。链接数据库的方式:
mysql -h localhost -u transwarp -p$(cat /etc/transwarp-manager/master/db.properties | grep io.transwarp.manager.db.password | awk -F = '{print $2}') -S /var/run/mariadb/transwarp-manager-db.sock -D transwarp_manager执行如下 SQL 查看节点 ip :
# 获取 service.cluster.ip.range
# kubernete IP 为该网段第一个IP
select * from service_config where name='service.cluster.ip.range';
# 获取所有节点主机名和IP
select * from node;
# 获取 TOS MASTER 主机名和IP
SELECT n.*
FROM node n
INNER JOIN role r ON n.id = r.nodeId
WHERE r.type='TOS_MASTER';2.2 修改 host.txt
结合之前获取的信息,按照以下格式更新 host.txt 文件,注意 master 节点区分:
host.txt
# 主机名 IP 角色名 ssh端口 连接用户 用户密码
node01 192.168.0.115 master 22 test 123456
node02 192.168.0.113 master 22 test 123456
node03 192.168.0.114 master 22 test 123456
node04 192.168.0.112 worker 22 test 1234562.3 更新脚本
更新 gencerts/gen-certs.sh ,在脚本的第16行,注释原有svc的取值,改为 svc={kubernete IP}
gencerts/gen-certs.sh
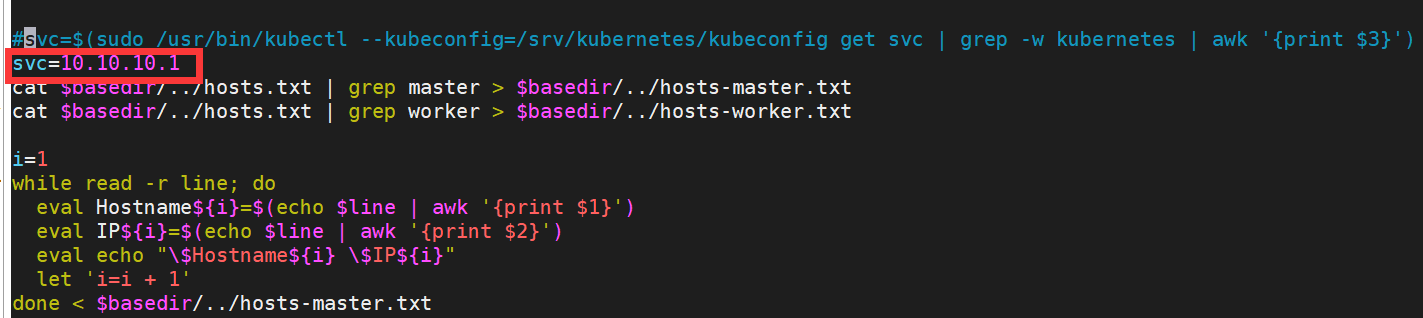
# 以下为示例,请按照实际IP情况填写,该IP填写错误将导致TOS启动失败
#svc=$(sudo /usr/bin/kubectl --kubeconfig=/srv/kubernetes/kubeconfig get svc | grep -w kubernetes | awk '{print $2}')
svc=10.10.10.1
cat $basedir/../hosts.txt | grep master > $basedir/../hosts-master.txt
cat $basedir/../hosts.txt | grep worker > $basedir/../hosts-worker.txt这里的 svc 一定要修改为第 2.1 步获取的 kubernete IP
新增 ex-wakeup.sh: 点击下载 ex-wakeup.sh
该脚本实现两个内容, 一是使用新的ca证书重启docker, 二是逐个重启etcd:
3、CA更新唤醒TOS
在执行脚本时,可能会有部分异常情况,请参照文档的 6 已知问题 部分进行处理
bash gencerts/gen-certs.sh
bash ex-wakeup.sh
bash 03-distribute-new-certs.sh
以上三个脚本执行完成后,手动去 每个 TOS MASTER 重启 haproxy 服务,重启完成后,kubectl get no 命令应该可以执行了。
# 重启 每个 TOS MASTER 的haproxy
systemctl restart haproxy
# 确认 haproxy 服务启动
systemctl status haproxy
# 确认kubectl 命令恢复
kubectl get no回到 ca-renewal 目录下,继续执行以下脚本:
bash 02-check-secrets-ca.sh
bash 04-recreate-secrets.sh
bash 05-restart-sa-pods.sh
bash 06-restart-webhook-pods.sh
bash 07-restore-config-with-newca.sh
bash 08-update-ca-trust.sh
bash 09-update-manager-db.sh
bash 09-update-manager-metainfo.sh3.5 后续操作
以上步骤操作完成后,请确认K8S服务是否恢复正常,可以通过以下命令确认:
# 查看 k8s pod
kubectl get po -nkube-system4.手动修改tos的metainfo文件内容
- 确认tos 版本
docker images |grep etcd
- 找到tos的metainfo文件:
比如上图中,对应的 tos 版本为 tos-2.1.5
cd /var/lib/transwarp-manager/master/content/meta/services/TOS/tos-2.1.5
# 如果 service 目录不存在,则是services_imported
cd /var/lib/transwarp-manager/master/content/meta/services_imported/TOS/tos-2.1.5- 修改metainfo.yaml
PS:一定要注意yaml 文件的格式和内容,复制粘贴修改 metainfo 时,一定要确认修改后的内容和缩进必须符合 yaml 要求。
如果修改后,点击 Manager 页面的 TOS 服务,页面出现,未使用 TOS,需要安装一个TOS服务,则需要检查一下 metainfo.yaml 内容和格式。
vi metainfo.yaml找到 TOS_SLAVE 下的 type: Scaleout,在最后面加上以下内容,注意跟其他的directive并列,注意缩进保持一致
- 如果Manager版本在8.0及以后,直接使用下面的metainfo
- directive: !
script: |
<#assign distros = ["BCLINUX4EULER21", "EULER20", "EULER22", "KYLIN10", "NEOKYLIN7", "RHEL7", "RHEL8", "ROCKY8", "ROCKY9", "UOS1050A", "UOS1050E", "UOS1060E"]>
<#if distros?seq_contains(.data_model['node.distro'])>
(/bin/cp -f /srv/kubernetes/ca.pem /etc/pki/ca-trust/source/anchors/) && update-ca-trust
<#else>
(/bin/cp -f /srv/kubernetes/ca.pem /usr/local/share/ca-certificates/) && update-ca-certificates

- 如果是8.0以前的版本,判断扩容节点是什么操作系统
uname -a
cat /etc/os-release["BCLINUX4EULER21", "EULER20", "EULER22", "KYLIN10", "NEOKYLIN7", "RHEL7", "RHEL8", "ROCKY8", "ROCKY9", "UOS1050A", "UOS1050E", "UOS1060E"]
如果在以上列表里面,使用以下内容修改。
- directive: !
script: |
(/bin/cp -f /srv/kubernetes/ca.pem /etc/pki/ca-trust/source/anchors/) && update-ca-trust 如果不在,使用以下内容修改。
- directive: !
script: |
(/bin/cp -f /srv/kubernetes/ca.pem /usr/local/share/ca-certificates/) && update-ca-certificates - 重启 manager 生效。
systemctl restart transwarp-manager5.TOS 配置服务
登录 Manager 页面,点击上方全局服务,TOS,然后配置服务。

如果扩容的节点是混部的,那么根据节点不同的操作系统,在执行扩容角色,tos slave启动失败后,手动将主节点下的/srv/kubernetes/ca.pem拷贝到对应目录,执行指令,后重启docker
6. 检查
0、检查当前集群TOS证书过期时间,登录集群任意节点,执行下面的命令
openssl x509 -text -in /srv/kubernetes/ca.pem |grep Not如果显示是 2120 年过期,则表示续签成功。

1、检查 bootstrap
head /srv/kubernetes/bootstrap.kubeconfig输出的 certificate-authority-data 最后几位是 :RU5EIENFUlRJRklDQVRFLS0tLS0K 代表续签完成。
